Свако у Србији који пише на рачунару има проблем са обликом неких наших ћириличних слова. То је нарочито изражено када користимо курзив (italic) слова која су нам инсталирана на рачунару.
Нека ћирилична слова писана курзивом у различитим фонтовима делују нам чудно.
Зашто је то тако и како решити проблем?
Развој електронског записа текста
Први рачунари прављени су претежно за енглеско говорно подручје и имали су подршку само за енглески alfabet, за бројеве, заграде и још понеки контролни знак, што је чинило укупно 128 могућих слова (у 7 бита).
То је био тзв. ASCII или US-ASCII (амерички) стандард.
Касније је скуп знакова проширен на 256 (8 бита), а „горњих“ 128 знакова је било коришћено за додатне знакове. Из неке навике је и овај проширени ASCII називан ASCII, тако да ту често долази до забуне. Да би постојала подршка за више језика, смишљане су тзв. кодне стране (Code Page) које дефинишу понашање тог додатног скупа слова. Основна кодна страна на персоналним рачунарима (PC437) у том горњем скупу дефинише разне графичке знакове за цртање текстуалних прозора и слично. Касније је развијено још пуно кодних страна које подржавају одређене језике. Тако постоје Латин1 (ISO-8859-1) за латинична писма Западне Европе (Француска, Немачка, Шпанија, …), Латин2 (ISO-8859-2) и Windows-1250 за латинична писма Источне Европе (наша латиница и сл.).
Основни проблем са кодним странама је то што се међусобно искључују, тј. цели документ мора да буде написан истим писмом. То углавном није проблем реализовати, али ако би било потребно помешати два писма, где заједно постоји и текст на српском, на енглеском и на француском, наилази се на проблем. Због тога се дошло до идеје да се направи јединствени запис за све језике – Уникод.
УНИКОД
Постоји више верзија Уникода. Основна верзија је двобајтни формат записа до 216 = 65536 знакова. Њен назив је UCS-2 зато што користи два октета, односно два бајта. Са тих 65536 знакова решен је проблем записа скоро свих постојећих писама (укључујући чак и нека измишљена, као на пример клингонско писмо). Овај тип Уникода се назива Plain UCS-2 или UTF-16.
Евидентан је проблем алокације (доделе) простора за Уникод-кодирану поруку на медијуму који се користи. Ако је реч о неком документу на диску, он ће да заузима дупло више простора него конвенционалан документ јер ће се сваки знак записивати са два бајта уместо само са једним. Ако је реч о преносу података преко рачунарске мреже, биће потребно пренети дупло више података, па ће самим тим и пренос да траје дупло више (односно да кошта дупло више).
Да ли је то сувише велика цена за универзално писмо и да ли постоји неки начин да се тај проблем превазиђе и избегне.
Као решење увек стоји могућност да се записује неком одговарајућом кодном страницом и троши бајт по знаку, ако није неопходно коришћење више писама у истом документу.
Друго решење је коришћење тзв. трансформационих шема за погоднији запис и пренос података коришћењем Уникода.
Прво је развијена Уникод трансформациона шема са основном јединицом од 8 бита (UTF-8). Помоћу ње се знак записује у једном, два или три бајта, у зависности од тога о ком је знаку реч. Ова трансформациона шема је превасходно згодна за употребу у језицима који користе латиницу.
 У Уникоду српски и македонски језик, односно њихова ћириличка писма, нису тзв. „грађани првог реда”. При дизајну Уникода почетком 1990-их година, није узето у обзир да се ћириличка писма мање-више разликују у дизајну појединих слова. То се испољава у курзиву (искошено или полуписано), али, као што се види на слици, и са малим словом б у основном режиму. У руској верзији оно веома наликује броју 6, док у српској верзији то није случај, осим у изузетно малим величинама.
У Уникоду српски и македонски језик, односно њихова ћириличка писма, нису тзв. „грађани првог реда”. При дизајну Уникода почетком 1990-их година, није узето у обзир да се ћириличка писма мање-више разликују у дизајну појединих слова. То се испољава у курзиву (искошено или полуписано), али, као што се види на слици, и са малим словом б у основном режиму. У руској верзији оно веома наликује броју 6, док у српској верзији то није случај, осим у изузетно малим величинама.
Због величине тржишта (Руска Федерација и околне земље из бившег Совјетског Савеза, као и Бугарска), већина фонтова која садрже ћирилицу, преферира руску ћирилицу на стандардним местима Уникода, односно руски дизајн графије, па српски и македонски језик највише трпе због овога. Иако су велика предузећа као што су Адоби системс (Adobe Systems) и Мајкрософт (Microsoft) упозната са овим проблемом, још увек се не зна да ли ће и када и ови језици постати „грађани првог реда” у систему Уникод.
У међувремену, решење може пружити технологија као што је Опентајп (OpenType, нарочито њено својство лоцл (locale)), софтвер који је подржава и модерни фонтови који садрже исправна српска/македонска слова. Добри примери су оперативни систем ГНУ/Линукс (GNU/Linux), канцеларијски пакет Либреофис (LibreOffice) под Линуксом и веб-читач Мозила Фајрфокс (Mozilla Firefox).

Најчешћи проблем који се јавља кад се у тексту појаве ћирилична курзивна (italic) слова т, п, г, д јер су то руски облици, које је својим реформама у употребу увео Петар Велики.
Код нас су се развиле другачије варијације тих слова и зато у нашим ћириличним текстовима не би требало да се појављују руски облици. Они одступају од стандардног облика нашег књижног писма, што утиче на читљивост, као и на графички изглед сложеног текста. Руска слова се и поред тога често налазе у нашем слогу, а један од разлога је незнање: многи људи су равнодушни према изгледу писма које користе и нису упознати са разликом између наших и руских облика. Други разлог је техничке природе, јер ћирилице које потичу из иностранства, укључујући и уникод фонтове који се користе на Интернету, садрже само руску варијанту слова, те онај ко их користи често нема избора.
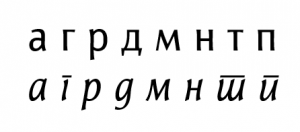
Данас има све мање оправдања за коришћење руских верзија слова уместо наших, поготово ако су текстови слагани фонтовима који садрже и наша ћирилична слова, а који долазе у пакету са програмима који подржавају рад са нашим словима. Развој технологије, ширење знања као и брига за наше писмо могу учинити да српска ћирилица на рачунарима буде равноправна са осталим писмима.
За нас, најчешће кориснике, наjважније је да постоје и готови фонтови које можемо инсталирати на нашим рачунарима
Ако желите да курзив буде приказан и штампан у исправном облику инсталирајте фонтове са исправним пакетом слова.
Упутство:
• Зиповане архиве преузмите (download)
• Сваку архиву распакујте (препорука у засебан фолдер)
• Свака архива садржи 4 датотеке типа *.otf или *.ttf (основни облик, bold, italic i bold italic). Двокликом на сваку датотеку (file) отвара се прозор који нуди опцију install.
препоручујем TTF
• Остаје вам да у свом Wordu одаберете одговарајући фонт.
Не заборавимо: Српска латиница или абецеда има 30 графема (слова) од којих су само три диграфа (двословна): DŽ, LJ, NJ. Слово Đ се не пише као DJ.